Introduction:
RAG combines an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
So you can say RAG is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process.
RAG can refer to several different things depending on the context. Here are a few common meanings:
1. Red, Amber, Green (RAG): In project management and reporting, RAG is a color-coding system used to quickly convey the status or health of a project or task.
2. RAG Analysis: This is a method used in risk assessment or decision-making. It involves categorizing risks or options as Red, Amber, or Green based on their level of severity, impact, or desirability. It helps prioritize actions or choices.
3. Random Access Generator (RAG): In some technical contexts, RAG might refer to a system or algorithm that generates random access patterns or data, often used in computer science or information retrieval.
4. Resource Allocation Graph (RAG): In the context of operating systems and computer science, a Resource Allocation Graph is used for deadlock detection. It’s a directed graph that represents resource allocation and request relationships among processes in a system.
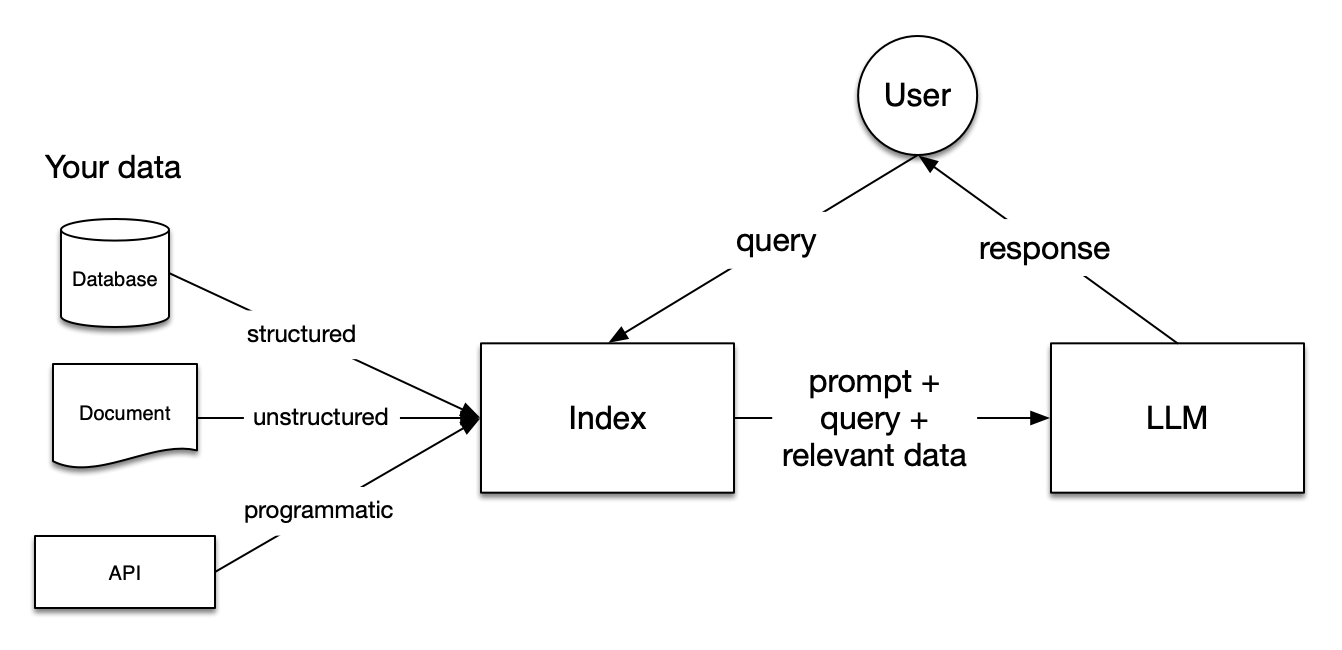
You can break the Retrieval Augmented Generation process down into the following steps:
Loading: This process involves transferring your data from its original location – which could be text files, PDFs, other websites, databases, or APIs – into your processing pipeline.
Indexing: This step involves creating a data structure that enables you to search through the data. In language models, this typically involves creating vector embeddings (we’ll talk about these more in a minute), which are numerical representations capturing the meaning of your data.
Storing: After indexing your data, it’s common practice to store the index and any associated metadata. This storage prevents the need for re-indexing in the future.
Querying: Depending on the chosen indexing strategy, there are multiple ways to use language models to conduct searches. These include sub-queries, multi-step queries, and hybrid approaches.
Evaluation: An essential phase in any pipeline is to assess its effectiveness. This can be compared to other strategies or evaluated for changes over time. Evaluation provides objective metrics on the accuracy, reliability, and speed of your query responses.
Benefits of Retrieval-Augmented Generation (RAG)
Enhanced LLM Memory
RAG addresses the information capacity limitation of traditional Language Models (LLMs). Traditional LLMs have a limited memory called “Parametric memory.” RAG introduces a “Non-Parametric memory” by tapping into external knowledge sources. This significantly expands the knowledge base of LLMs, enabling them to provide more comprehensive and accurate responses.
Improved Contextualization
RAG enhances the contextual understanding of LLMs by retrieving and integrating relevant contextual documents. This empowers the model to generate responses that align seamlessly with the specific context of the user’s input, resulting in accurate and contextually appropriate outputs.
Updatable Memory
A standout advantage of RAG is its ability to accommodate real-time updates and fresh sources without extensive model retraining. This keeps the external knowledge base current and ensures that LLM-generated responses are always based on the latest and most relevant information.
Source Citations
RAG-equipped models can provide sources for their responses, enhancing transparency and credibility. Users can access the sources that inform the LLM’s responses, promoting transparency and trust in AI-generated content.
Reduced Hallucinations
Studies have shown that RAG models exhibit fewer hallucinations and higher response accuracy. They are also less likely to leak sensitive information. Reduced hallucinations and increased accuracy make RAG models more reliable in generating content.
These benefits collectively make Retrieval Augmented Generation (RAG) a transformative framework in Natural Language Processing, overcoming the limitations of traditional language models and enhancing the capabilities of AI-powered applications.
Working Of RAG:
RAG consists of two distinct phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve relevant information from external knowledge bases. This information is then used in the generative phase, where the LLM synthesizes an answer based on both the augmented prompt and its internal representation of training data.
Phase 1: Retrieval
- Relevant information is retrieved from external sources based on the user’s prompt or question.
- Sources vary depending on the context (open-domain internet vs. closed-domain enterprise data).
Phase 2: Content Generation
- The retrieved information is appended to the user’s prompt and fed to the LLM.
- The LLM generates a personalized answer based on the augmented prompt and its internal knowledge base.
- The answer can be delivered with links to its sources for transparency.